3/REMOTE-LOG
- Status: draft
- Editor: Oskar Thorén <oskarth@titanproxy.com>
- Contributors:
- Dean Eigenmann <dean@status.im>
A remote log is a replication of a local log. This means a node can read data that originally came from a node that is offline.
This specification is complemented by a proof of concept implementation1.
Definitions
| Term | Definition |
|---|---|
| CAS | Content-addressed storage. Stores data that can be addressed by its hash. |
| NS | Name system. Associates mutable data to a name. |
| Remote log | Replication of a local log at a different location. |
Wire Protocol
Secure Transport, storage, and name system
This specification does not define anything related to: secure transport, content addressed storage, or the name system. It is assumed these capabilities are abstracted away in such a way that any such protocol can easily be implemented.
Payloads
Payloads are implemented using protocol buffers v3.
CAS service:
syntax = "proto3";
package vac.cas;
service CAS {
rpc Add(Content) returns (Address) {}
rpc Get(Address) returns (Content) {}
}
message Address {
bytes id = 1;
}
message Content {
bytes data = 1;
}
NS service:
syntax = "proto3";
package vac.cas;
service NS {
rpc Update(NameUpdate) returns (Response) {}
rpc Fetch(Query) returns (Content) {}
}
message NameUpdate {
string name = 1;
bytes content = 2;
}
message Query {
string name = 1;
}
message Content {
bytes data = 1;
}
message Response {
bytes data = 1;
}
Remote log:
syntax = "proto3";
package vac.cas;
message RemoteLog {
repeated Pair pair = 1;
bytes tail = 2;
message Pair {
bytes remoteHash = 1;
bytes localHash = 2;
bytes data = 3;
}
}
Synchronization
Roles
There are four fundamental roles:
- Alice
- Bob
- Name system (NS)
- Content-addressed storage (CAS)
The remote log protobuf is what is stored in the name system.
"Bob" can represent anything from 0 to N participants. Unlike Alice, Bob only needs read-only access to NS and CAS.
Flow
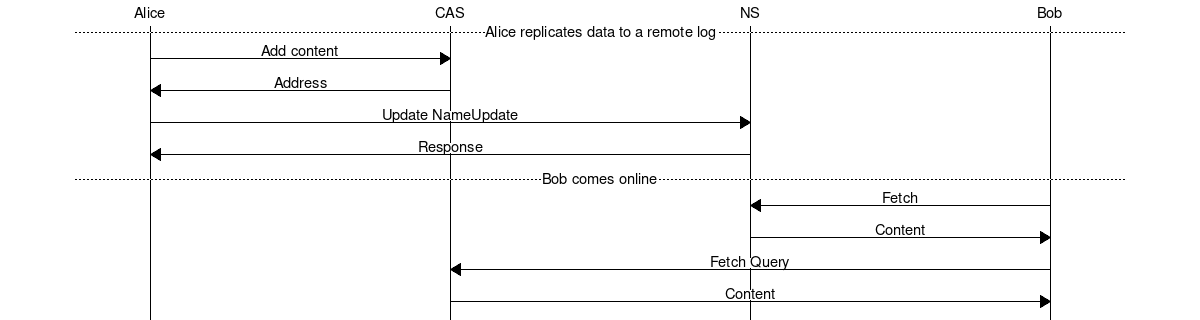
Remote log
The remote log lets receiving nodes know what data they are missing. Depending on the specific requirements and capabilities of the nodes and name system, the information can be referred to differently. We distinguish between three rough modes:
- Fully replicated log
- Normal sized page with CAS mapping
- "Linked list" mode - minimally sized page with CAS mapping
Data format:
| H1_3 | H2_3 |
| H1_2 | H2_2 |
| H1_1 | H2_1 |
| ------------|
| next_page |
Here the upper section indicates a list of ordered pairs, and the lower section
contains the address for the next page chunk. H1 is the native hash function,
and H2 is the one used by the CAS. The numbers corresponds to the messages.
To indicate which CAS is used, a remote log SHOULD use a multiaddr.
Embedded data:
A remote log MAY also choose to embed the wire payloads that corresponds to the native hash. This bypasses the need for a dedicated CAS and additional round-trips, with a trade-off in bandwidth usage.
| H1_3 | | C_3 |
| H1_2 | | C_2 |
| H1_1 | | C_1 |
| -------------|
| next_page |
Here C stands for the content that would be stored at the CAS.
Both patterns can be used in parallel, e,g. by storing the last k messages
directly and use CAS pointers for the rest. Together with the next_page page
semantics, this gives users flexibility in terms of bandwidth and
latency/indirection, all the way from a simple linked list to a fully replicated
log. The latter is useful for things like backups on durable storage.
Next page semantics
The pointer to the 'next page' is another remote log entry, at a previous point in time.
Interaction with MVDS
vac.mvds.Message payloads are the only payloads that MUST be uploaded. Other messages types MAY be uploaded, depending on the implementation.
Acknowledgments
TBD.
Copyright
Copyright and related rights waived via CC0.